DeepDive LLM 3편 - Reinforcement Learning


- 1편 - 사전 학습 (Pre Training)
- 2편 - Supervised Fine Tuning
- 3편 - Reinforcement Learning
Reinforcement Learning
Pretrain, SFT 에 이어서 세번째 단계는 Reinforcement Learning (RL, 강화학습) 입니다.
비유를 해보자면, pretrain은 그냥 책을 읽는 것이고요, SFT는 예제 문제와 이미 작성된 해설을 보는 것입니다. RL 은 해설이 없는 문제를 직접 풀어보는 것입니다. 어떻게 풀든 방법에 자유도가 있죠. 그냥 풀어보는 것입니다.
LLM 에게 문제를 풀어보도록 하기
SFT 에서 풀어봤던 수학 문제를 Llama-3.2-3B-Instruct 에게 여러번 풀려봤습니다.
오렌지의 가격은 4달러이기 때문에, 오렌지를 구입한 총 비용은 177 * 4 = 708달러입니다.
사과와 오렌지를 구입한 총 비용은 869달러이기 때문에, 사과의 가격은 869 - 708 = 161달러입니다.
161달러를 사과에 사용한 비용을 23개 사과로 나눈 결과, 161 / 23 = 7달러가 사과당 가격입니다.
결론적으로, 사과는 7달러에 판매됩니다.
맞았습니다! 다시 풀려볼까요?
사과와 오렌지의 총 가격은 869 + 708 = 1577달러입니다.
사과는 23개가 있으므로, 사과의 가격은 1577 / 23 = 68.57달러입니다.
이번엔 틀렸습니다.
이렇게 틀릴 수도 있고, 맞을 수도 있어요. 풀이도 제 각각이죠. 다양하게 풀어보고 정답을 채점을 시켜보면, 어떤 방식으로 풀어보는 게 잘 풀리는지 감을 잡을 수가 있습니다.
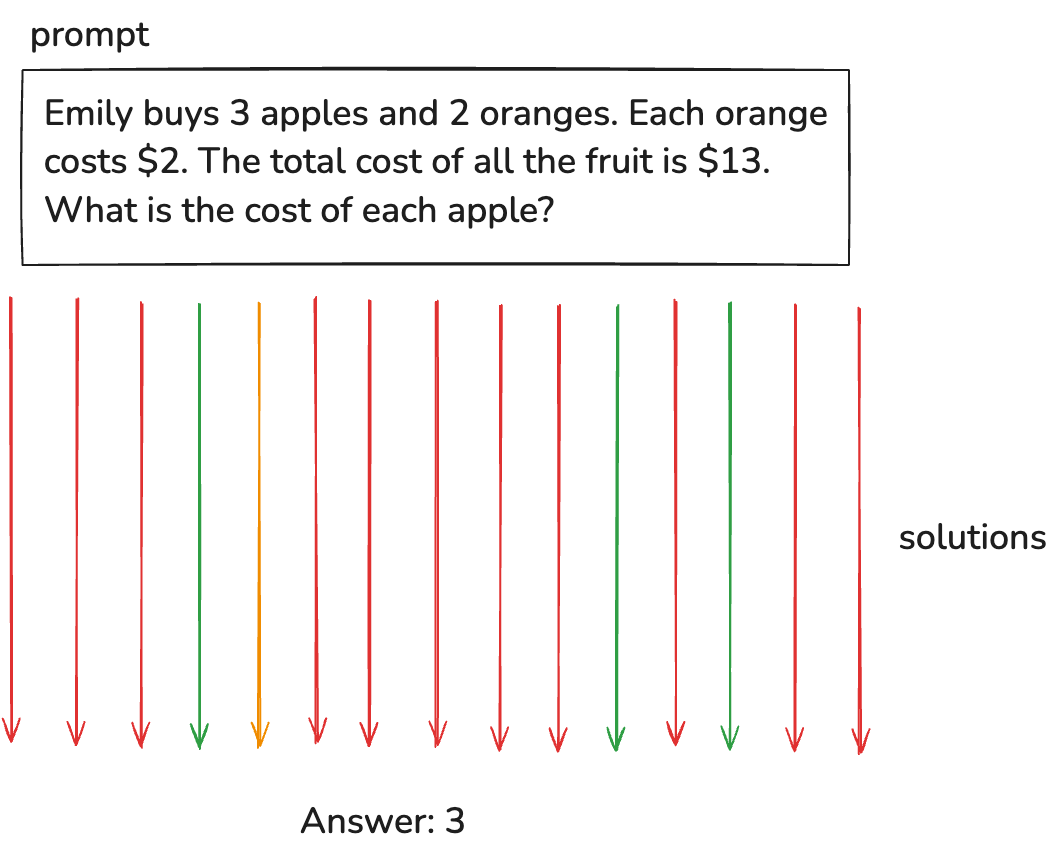
그림으로 보면 이와 같습니다. 하나의 프롬프트에 대해서 다양하게 풀어보고요, 그중에 맞는 놈도 있을 거고 틀린 놈도 있을 거에요. 맞는 놈을 기준으로 보상을 주고 학습 시키는 것이 강화학습입니다.
여기서, 1. 맞는 놈들 중에 최선의 답을 찾아야하고요, 2. 맞는지 틀리는지 정답을 매길 수 있어야 합니다.
SFT 는 풀이 방법까지 정해주는 것이라면, RL 은 풀이 방법은 자유인 점이 다릅니다. 인간이 생각하지 못했던 풀이에 도달할 수 있기 때문에 더 포텐셜은 더 좋습니다.
DeepSeek-R1 의 Reinforcement Learning
이 방법을 적극적으로 활용하고, 성공했고, 꽤 많이 공유한 모델이 DeepSeek-R1 입니다. 미국 증시 시장에도 아주 큰 영향을 끼쳤죠?
참고로 미국 증시에 큰 영향을 끼친 요소는 크게 두가지 입니다.
- DeepSeek-V3 라는 꽤 좋은 베이스 모델을 100억 안쪽의 비용으로 성공 시켜서
- DeepSeek-R1 이라는 Reasoning 모델을 RL 로 성공 시켜서
여기서는 후자에 대해 이야기 하겠습니다.
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
페이퍼 의 제목 부터 Reinforcement Learning 입니다. 성과를 요약해보겠습니다.
OpenAI의 o1 이 24년에 나왔습니다. Reasoning 모델로 생각을 오래오래 하면서 어려운 문제 (주로 수학이나 코딩) 를 잘 풀어내는 똑똑한 친구입니다. 이 모델은 RL 로 만들었다고 공개 했는데, 어떻게 만들었는지 비공개였습니다. DeepSeek-R1 공개 시점에서는 사실상 최고의 모델이었죠.
이때 DeepSeek-R1 이 나왔고, o1 이랑 꽤 비슷한 수준의 모델이고, 비슷한 방식의 Reasoning 모델 입니다. 그리고, 어떻게 만들었는지 공개했죠. 이제 모든 사람들이 알게 된거죠, 저렇게 만들면 되는 구나!
디테일한 내용들은 저희가 다룬 내용이 있으니 참고하시고요, 자세한 디테일은 여기 포스트에서는 생략하겠습니다.
DeepSeek-R1의 페이퍼로 돌아와서, 재밌는 지점들을 보겠습니다.
위에서 설명한 대로 RL 를 합니다. 다양하게 문제들을 풀려보고, 정답을 맞춘 결과물에 대해 보상을 주고 학습하고, 쭉 반복하다보면...
아래와 같이 학습을 반복할 수록 평균 대답 길이가 늘어나요. 토큰을 많이 사용하고, 연산을 많이 사용하면서, 풀이를 중얼중얼 하면서 문제를 풀어낼 수록 더 정답률이 올라가는 것이죠. 이것이 Reasoning 모델의 탄생입니다. 알아서 생각하는 시간을 더 길게 가져가게 됩니다.
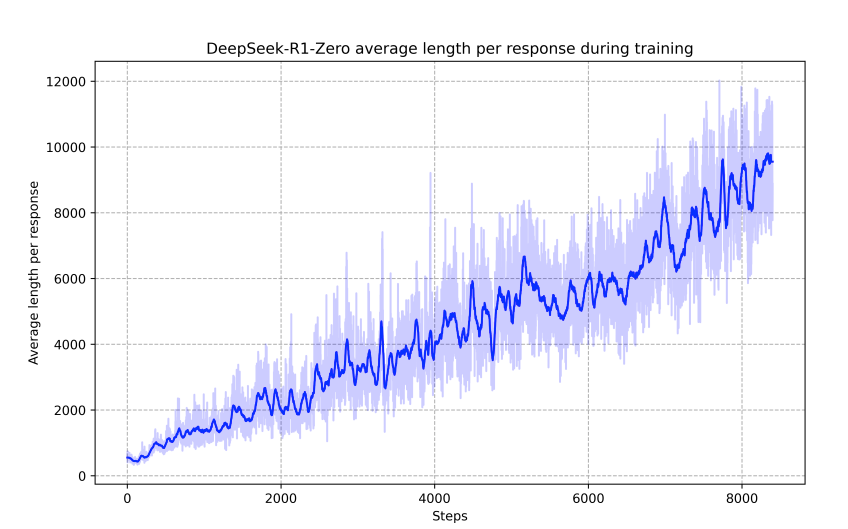
통계적인 부분말고도, 학습 중간 과정에서의 모델 output 을 관찰해보면 다음과 같은 "aha moment" 를 볼 수 있습니다.

알아서 답변을 하다가 본인이 틀린 지점을 찾고 다시 해결하는 과정이죠. 사람과 비슷하죠? 저렇게 하라고 알려주지 않았는데, RL 만 했을 뿐인데, 알아서 aha moment 가 생긴다는 것이 신기하긴 합니다.
궁금하신 분들은 https://chat.deepseek.com/ 에 가셔서 가입하시고 "think" 버튼을 누르고 써보시면 저러한 생각 과정을 다 볼 수 있습니다. 참고로 OpenAI o1 같은 경우는 생각 과정을 숨겼습니다. API 사용단에서도 reasoning 토큰을 받아볼 수 없고, chatgpt 서비스에서는 생각 과정을 재가공해서 사람들에게 일부만 보여줍니다.
deepseek 서비스가 개인 정보 관련하여 우려가 되시는 분들은 모델만 다운받아서 직접 돌려보시는 방법도 있습니다.
AlphaGO 에서도 봤던 RL의 효과
그 유명한 알파고도 RL 을 사용했습니다. 이건 제가 9년전 대학원생 시절에도 본 블로그에서 원리를 포스트한 바 있는데요.

제가 무려 2016년 3월에도 비슷한 평가를 했네요.
가장 큰 의미는 reinforcement learning 이 결과적으로 잘 된다는 것이다.
사람들의 기보를 보고 비슷하게 따라두는 것 을 넘어선 것이다. 자신들끼리의 모의 경기를 통해서 사람이 두지 않는 좋은 수를 찾았다.
알파고도 DeepSeek-R1 과 마찬가지로 통계적인 면과 하나의 사례를 통해 RL 의 효과를 보겠습니다.
알파고 제로 페이퍼 에서 발췌해왔습니다.
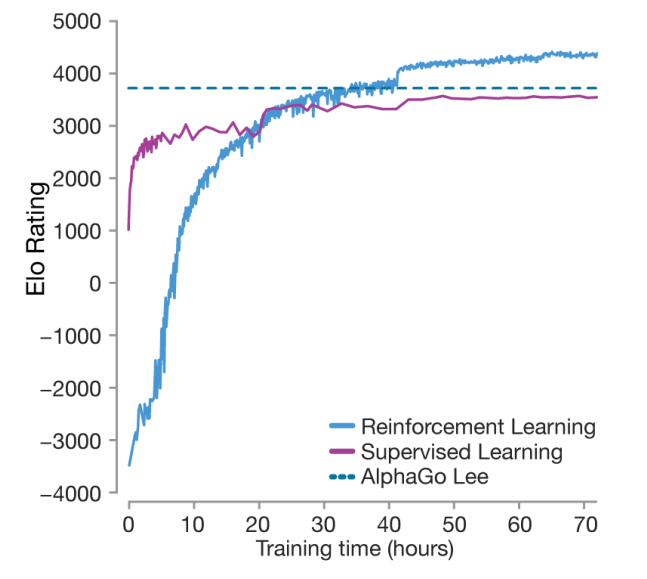
알파고도 버전별로 계속 진화를 했는데요. AlphaGo Lee 가 이세돌과 붙었던 "그 알파고" 입니다. 대략적으로 비유하자면 인간 최고수 수준 이라고 볼 수 있겠습니다. Supervised Learning은 고수들의 기보를 보고 배우는 것인데요 이세돌 수준을 넘을 수 없습니다. 반면 Reinforcement Learning 을 도입하면 인간 최고수 수준을 뛰어 넘을 수가 있죠.
RL을 도입해야 인간 최고수 기보에서는 찾을 수 없었던 새로운 좋은 방법들을 찾아낼 수 있다. 이 내용이 핵심입니다.
실제 이세돌과의 대결에서도 이런 순간이 보입니다. "Move 37" 이라고 불리는 순간인데요 짧은 영상을 첨부하니 한번 보시면 좋겠습니다, 참고로 이 영상은 알파고 다큐영상의 일부인데 2시간 정도 되는 아주 볼만한 다큐입니다. 지금은 무료로 유투브에서 보실 수 있습니다.
바둑 전문가들이 모두 알파고의 한 수에 놀랍니다. 이세돌도 보고 의아해하죠. 인간이라면 절대 두지 않을 수 인가 봅니다. (저는 바둑을 잘 몰라서...) 아무튼 이런 수가 SFT 로는 나올 수 없는 수 입니다. 인간 고수들은 몰랐던 방법이고, RL 로 알파고 알아서 찾아낸 수 입니다.
요즘은 사람들이 알파고를 보고 따라 바둑을 배운다고 하죠.
RLHF (Reinforcement Learning by Human Feedback)
대표적인 Reinforcement Learning 방법 입니다. 세간에는 GPT4가 다른 모델들에 비해 똑똑한 이유로 알려져있죠. 앞서 예시를 든 수학 문제 같은 경우는 정답이 있어서 뭐가 맞은 대답인지 쉽게 평가가 됩니다. "유머"를 예시로 들어보죠.
"유머"는 정답이 없어요. 다양한 유머를 만들게 한 다음에 웃긴 거를 골라서 그 방향으로 보상을 주고 RL 을 해야합니다. LLM 이 만든 다양한 유머들을 사람들이 다 평가해야하는데, 그게 문제죠.
그래서 OpenAI 가 한 방법!
사람의 평가를 흉내내는 Reward Model 을 또 만들어 버립니다

실제 사람의 평가 점수와 비슷하게 평가를 내려줄 수 있는 reward model을 만들 수 있다면! RL 를 쭉쭉 돌릴 수가 있죠. 당연한 이야기이지만 좋은 reward model을 만드는 것이 어렵습니다.
RLHF 의 장점은 RL을 모든 도메인으로 확장할 수 있다는 점 입니다.
수학, 코딩 처럼 명확한 답이 정해져 있지 않은 유머나 시를 작성하는 것, 이런 행위들에도 RL 을 적용할 수가 있어요.
그리고 사람은 "좋은 시를 써!" 라고 하는 것보다 "이 시들 중에서 좋은 거 순서대로 나열해!" 를 훨씬 잘 합니다. 그래서 단계적으로 발전이 가능하죠. 카파시 선생님은 이걸 "discriminator - generator gap" 이라고 하시네요.
RLHF 의 단점은 RL 이지만 포텐셜이 RL 이 아니라는 점 입니다.
LLM 입장에서는 reward model을 뚫기만 하면 됩니다. reward model은 사람을 시뮬레이션 하는 것이라 완벽하지가 않아요. RLHF 를 돌리다보면 LLM 이 생각보다 reward model을 너무 금방 잘 뚫어버립니다.
계속 학습을 시키다 보면, "시를 써봐!" 했을 때 "the the the the the" 이런식으로 헛소리 하게 됩니다. 왜냐면 reward model 이 그게 좋다고 했거든요. 수만가지의 가능성 중에 reward model 이 실수로 좋다고 한 것을 찾아서 그대로 학습해 버립니다.이 문제는 과거의 GAN 에서도 있었던 문제입니다.
그래서 RL 이지만 포텐셜이 열려있지 못해요. 학습을 하다보면 좋아지다가 갑자기 망가집니다. 학습을 하다가 중간에 멈춰야 합니다. 안 뚫리는 좋은 Reward model 만들어야 하는데 너무 어렵습니다.
(참고) RLHF 방법이 PPO (Proximal Policy Optimization) 인데, 이 방법이 너무 어려워 DPO (Direct Preference Optimization) 기법이 대안으로 가장 많이 사용됩니다. 이 방법에 대한 내용은 본 포스트에서는 생략합니다.
정리
여기까지 LLM 의 학습 방식과 동작 방식에 대해 길~게 알아보았습니다.
tokenizer 부터 pretrain, SFT, RLHF 까지 보았네요. 저 개인적으로도 진짜 pretrain을 바닥부터 해본 경험은 없었기에 Fine Tuning 단계부터만 알고 있어서 정리하며 배운게 많았습니다.
Pre-Train도 한번쯤은 직접 해보고 싶다는 생각이 드네요. 기회되면 조만간 한번 해보고 공유하겠습니다.
더 디테일하게 들어가면 효율적으로 학습하기 위한 PEFT (Parameter Efficient Fine Tuning), 그 중 가장 많이 쓰이는 LoRA (Low Rank Adaptation), 그리고 위에서 언급했던 DPO (Direct Preference Optimization), 용도에 따라 필요한 CPT (Continued Pre Training), 실전에 들어가면 알게될 jinja 템플릿이나 Quantization 을 이용한 GPU 메모리 관리 등 다룰게 많이많이 있습니다. 차차 하나씩 다뤄보면 좋겠습니다.
기타 유용한 자료들
- LMSYS Arena
- Buttondown AI News
- Hyperbolic
- HuggingFace