DeepDive LLM 1편 - 사전 학습 (Pre-Training)


본 포스트 시리즈는 카파시 선생님의 영상 을 기반으로 정리한 내용입니다. 직접 유투브에서 다루기도 했으니 영상으로 보셔도 됩니다.
- 1편 - 사전 학습 (Pre-Training)
- 2편 - Supervised Fine Tuning
- 3편 - 강화 학습 (Reinforcement Learning)
LLM 의 Training
LLM을 만들 때는 크게 세 가지 주요 단계가 있습니다.
1. 사전 학습(Pre-Training)
- 인터넷 텍스트(웹 페이지, 위키, 책 등)에서 대규모 데이터를 수집해 모델에게 “Next Token Prediction”을 하도록 학습하죠.
- 결과물: 인터넷 텍스트 흐름을 확률적으로 흉내 내는 베이스(base) 모델
2. 지도 미세 조정(Supervised Fine-Tuning, SFT)
- 대화 형태(“사용자-어시스턴트” 쌍)의 고품질 데이터(사람이 작성하거나 모델이 초안 후 사람이 보정)를 사용해, 모델이 “대화형 어시스턴트 역할”을 하도록 추가 학습합니다.
- 결과물: 실제로 질문에 답해주는 Instruct 모델
3. 강화학습(RL) 혹은 RLHF 등 Post-Training 단계
- 답변을 실제로 평가(정답 비교 혹은 인간 피드백)한 뒤, “답변이 좋으면 점수를 높이는” 식으로 모델이 스스로 똑똑해지도록 학습합니다.
- 이때 수학 문제 풀이처럼 정답 검증이 명확한 경우에는 ‘진짜’ 강화학습(RL)로 모델 스스로 다양한 풀이 전략을 발견하게 만들 수 있습니다. DeepSeek R1 이 이렇게 했죠.
- 시/소설/요약 같은 정답이 명확하지 않은 경우에는 인간 평가(선호도)에 근접한 보상 모델(Reward Model)을 훈련해, 이를 기준으로 RL을 수행하는 RLHF 방식을 사용합니다.
이 세 과정을 거치면, 인터넷 텍스트 지식을 폭넓게 갖추면서도(Pre-Training), 사람처럼 대화형으로 질문에 답하고(SFT), 때로는 복잡한 문제까지 풀어내는(RL) 거대 언어 모델을 만들 수 있습니다. 이제 하나하나 자세히 보죠.
사전 학습 (Pre-Training)
The Fine Web - Data from Internet
Pre-train 단계에서는 당연히 엄청난 양의 데이터가 필요합니다. Foundation Model을 굽는 큰 회사들 (ex. OpenAI, Google, Antrophic) 은 양질의 큰 데이터셋을 구성했습니다.
참고 - OpenAI 의 크롤러, Antrophic의 크롤러
이런 역할을 하는 오픈 된 데이터셋 중 하나는 HuggingFace 의 FineWeb 입니다.

15-trillion tokens, 44TB 용량의 데이터 입니다. 어떻게 만들어졌는지 한번 보겠습니다.
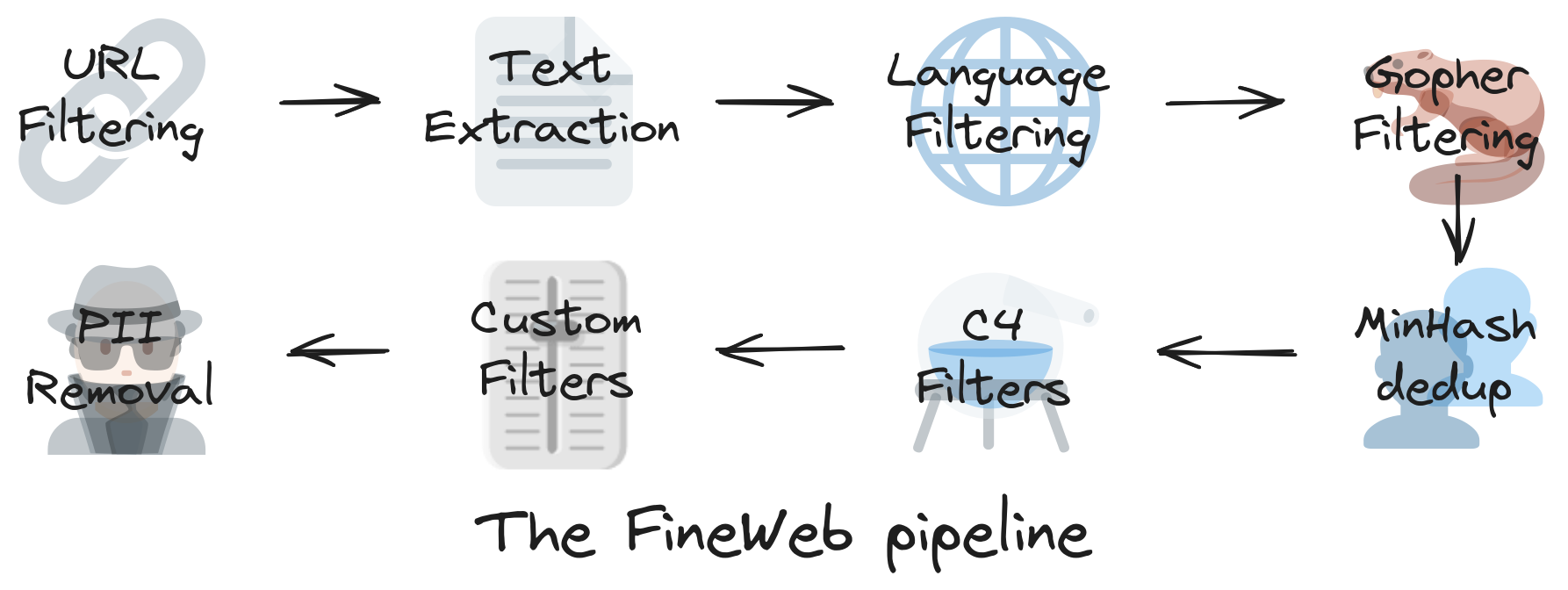
FineWeb 은 CommonCrawl 에서 시작합니다. CommonCrawl은 2007년에 설립된 비영리 집단으로 데이터를 400TiB 가까이 수집했고, 아무나 사용할 수 있다고 하네요? (이래도 되는 건가요?)
여기서 아래와 같은 작업을 더 합니다.
- 스팸/악성/음란성/품질 낮은 사이트 제외(블랙리스트 필터링)
- HTML 태그 제거 후 순수 텍스트만 추출
- 언어 classifier로 영어 텍스트만 남기거나, multi-lingual 타겟인 경우 다양한 언어를 비율에 맞춰 조절
- 개인정보나 중복 문서 제거 등
이 외에도 다양한 필터링 과정을 거쳐서 좋은 데이터를 만들어냅니다. 자세한 내용은 FineWeb 블로그 포스트를 보시면 아주 잘 나와있네요.
Tokenizer
이제 그 수 많은 글을 토큰 단위로 쪼개야합니다. 아래 tiktokenizer 에 들어가 보시면 여러가지 토큰 나누기를 해보실 수 있습니다.
토큰은 인간의 관점에서 보면 "단어" 랑 비슷하다고 생각하시면 됩니다. 글이라는 것은 어떠한 의미 단위의 데이터 (karpathy 는 여기서 symbol 이라고 하네요.) 가 sequential 하게 쭉 이어져 있는 것이죠. "단어 셋" 과 같은 느낌으로 "토큰 셋"을 준비한다면, 존재가능한 모든 토큰들의 sequence 로 "글" 이라는 데이터를 정의할 수 있습니다.
가장 멍청하게 하면 0,1 두 가지의 데이터로만 글을 표현 할 수도 있고요, utf-8 에 영어만 친다면 8bit (256가지의 symbol) 으로도 표현이 가능하겠죠?
GPT-4의 토큰 사전 (dictionary) 는 10만개가 조금 넘는 수준입니다. 모델마다 토크나이저가 다르고요, 당연히 호환이 잘 안됩니다.
Karpathy 영상에는 안 나와 있지만, 한국어 사용자인 우리는 한국어 토큰이 어떻게 되어있는지가 참 궁금하실 텐데요, tiktokenizer 에 한국어를 넣어보면 참 비효율적이라는 것을 어느 정도 느껴보실 수 있습니다.
"대화의 시작" 토큰 같은 특수 의미를 가지는 토큰들도 많이 있고요, 최근 reasoning 모델들을 "생각 시작", "생각 끝" 토큰도 있더군요. 로봇분야에는 "행동 토큰" 도 있고요.
Neural Net 의 I/O - Next Token Prediction
아마 이 글을 보시는 분들을 다 아실텐데요, LLM 의 문제 정의는 next token prediction 이죠.
존재 가능한 모든 토큰들 중 다음 토큰이 무엇일지 예측하는 classification 문제입니다.
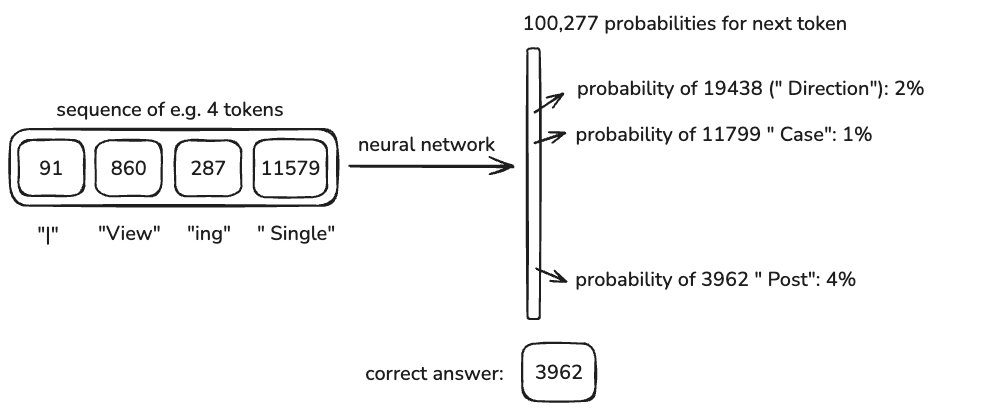
Input 으로 |Viewing Single 이 들어오면, 다음 토큰 예측 값은 Post 여야 하는 것이죠.
실제로 이 과정을 어떻게 하냐! 요즘엔 모두 트랜스포머로 합니다.
이 링크에 들어가보시면, 트랜스포머가 어떤식으로 동작하는지 보실 수 있습니다. 참고로 decoder only transformer 로, GPT를 포함한 요즘 LLM 은 모두 이런 구조를 가지고 있습니다.
트랜스포머 구조에 대한 이야기는 너무 방대하므로 본 포스트에서는 생략합니다.
Demo: GPT-2 재현
Karpathy 선생님이 예전에 올렸던 영상입니다. GPT-2 를 재현하는 컨텐츠 였는데요. 너무 길어서 저도 다 보지는 않았습니다.
GPT-2 에 대해서 이야기를 한번 해보죠.
2019년에 나온 모델이고, OpenAI 가 Open 이던 시절... 에 나온거죠. 원 페이퍼 저자들을 보니 Dario Amodei 와 Ilya Sutskever 가 보이네요. (ㅋㅋㅋ)
ChatGPT 는 GPT-3 이후에 나온 서비스이고, LLM 자체도 GPT-3 부터 주목을 받았던 것으로 기억합니다. GPT-2 가 세상에 나오던 시기는 저도 잘 모릅니다.
재현하는 것을 요약하면, 1.6B 사이즈에 context length 는 1024 token, 100B token으로 pretrain 된 모델입니다. 지금 기준으로 보면 아주 아주 아주 귀엽네요.
재현 포스트 를 보면 H100 x 8 싱글 노드를 빌려서 24시간 동안 학습을 했습니다. 24년 여름 기준 $672 가 들었다고 하는데, 현 시점 (25년2월) 기준 국내 업체인 엘리스에서 가격을 대강 계산해보니 80 만원 정도이고 선불로 하면 60만원대로 가능하겠네요.
쿠팡에서 h100 쳐보니까 1대에 4000만원 정도에 파네요? 진짜 파는거 맞나요... 연락하라고 있는 상품 같긴합니다.
재미있는 점은 OpenAI 가 2019년에 GPT-2 를 만들때 $40,000 정도가 들었다고 합니다. GPU 가 계속 발전해서 FLOPS 당 가격이 싸진 점도 있지만, 양질의 데이터를 잘 모아둔 점도 있고, 소프트웨어에서 학습 코드를 잘 최적화 한 점도 있다고 이야기 하시네요.
Llama 3.1 Base 모델
자 이제 현시점으로 와보죠. 현 시점에 쓸만한 모델을 pre-train 단계에서 부터 수행하는 회사는 그리 많지 않습니다. 대표적으로는 GPT, Gemini, Claude 같은 closed 모델들이 있고요, Llama, DeepSeek, Qwen, 등 몇몇 모델들이 있습니다. 한국어 기준으로 보면 Upstage 의 Solar 나 LG의 엑사원 정도? 있습니다. 엑사원은 참고로 Llama 와 구조가 똑같고 데이터만 다르게 pre-train 했다고 들었는데 확실하지는 않습니다.
아무튼 2024년에 나온 Llama3.1 을 보겠습니다. 405B 모델이고 15T 토큰으로 학습되었습니다.
Llama 3.1 모델들을 보면 Base 모델과 Instruct 모델이 있습니다. Instruct 모델은 다음 SFT (Supervised Fine Tuning) 단계에서 설명을 하겠습니다. Llama 말고도 Open Weight 모델들은 Base 모델과 Instruct tuned 모델 두개를 제공하곤 합니다. (Instruct 모델만 제공하는 경우도 있습니다.)
Hyperbolic 이라는 서비스에 가서 테스트를 해보겠습니다.

GPU 를 대여해주기도 하고, 모델을 올려줘 놨기 때문에 쉽게 사용해 볼 수 있습니다. 405B 모델을 테스트하려면 너무 많은 GPU 가 필요해서 클라우드에서 대여를 하고 다운 받아 돌려야 하는데, 이걸 대신 해줘서 좋습니다. (물론 다른 서비스들도 많습니다.)
재밌는 점은 "Supply GPU" 가 있네요? 남는 GPU 클라우드에 대여하고 돈 받으시길 바랍니다. 저는 바로 Waitlist 등록했습니다.
다시 돌아와서 Base 모델 테스트를 해보죠.

"유비의 동생은 누구지?" 라고 질문했더니, 아주 망가졌습니다. 많은 분들이 ChatGPT 와 같은 서비스로 느꼈던 대답이랑은 사뭇 다르죠.
Instruct 모델에도 질문을 해보죠.
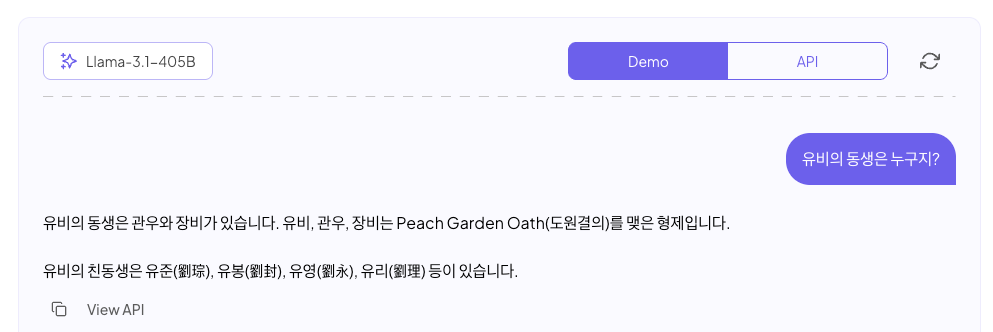
이게 정상이죠. 정말 깡 Pre-trained 만 된 Base 모델은 사용하기 대화형으로 사용하기는 충분하지 못하고, 그냥 정말 next token prediction을 하는 모델입니다. 글을 이어 쓰듯이 사용하는 정도만 쓸만합니다.
Wiki 문서와 같이 정확하게 봤던 문서들 정도는 잘 재현이 됩니다.

Few-shot 을 사용하면, In-Context Learning 을 시킬 수 있습니다.

Pre-trained 베이스 모델은 그냥 무수히 많은 글을 읽었기 때문에, 언제 끝내야 할 지도 모릅니다. 정해진 만큼 계속 대답을 할 뿐입니다.
베이스 모델에 대해 요약하자면,
- 토큰 레벨의 "인터넷 도큐먼트 시뮬레이터" 로, 인터넷 글들을 꿈꾸는 친구입니다
- 파라미터는 인터넷의 lossy 압축 파일이라고 봐도 되겠습니다
- Few-Shot 같은 방법으로 다양한 Application (예를 들면 번역)이 가능합니다
베이스 모델은 똑똑한 포텐이 있는 친구인데 교육이 좀 부족한 상태라고 보면 됩니다, 이제 추가 교육을 시켜서 잠재력을 끌어내고 업무에 투입시켜야합니다.