LangSmith, 사용 후기

최근 LangSmith (랭스미스) 를 RAG 시스템 개발/운영에 아주 유용하게 쓰고 있습니다.
동시에 SKT 에서 Langsmith 의 사용에 대한 강의도 진행했습니다. 그 내용은 책으로도 발간을 준비하고 있는데, 사용해보면서 느낀 점들을 정리해보겠습니다.

한 줄 요약: 꼭 쓰세요! 두 번 쓰세요! 대체 솔루션 많으니 그거라도 쓰세요!
먼저 LangSmith는 무엇인가. 이 글을 읽는 사람들은 관심이 있는 사람만 읽을 테니 LLM, FM, DevOps, RAG 이런 키워드들을 모두 안다고 가정하고 서술합니다.
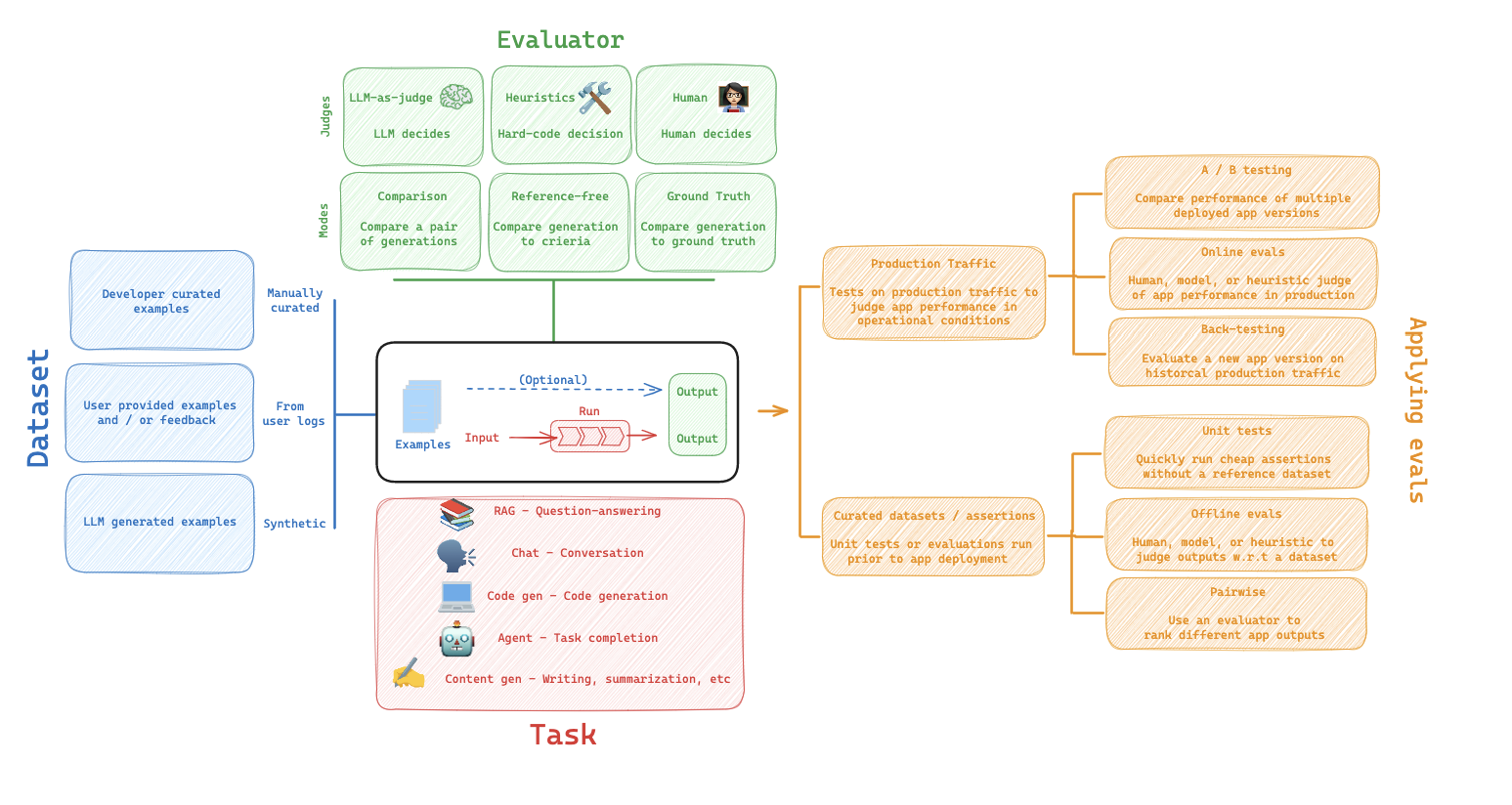
LangSmith 는 LLMOps 인가?
LangSmith는 굳이 분류를 하자면 LLMOps 도구 라고 볼 수 있습니다. DevOps의 LLM 버전 이라고 이해하면 되는데요. LLM 어플리케이션을 잘 만들고 운영하기 위한 도구입니다. 아래와 같은 기능들을 지원합니다.
- 현재 사용자가 어떻게 채팅을 하고 있는지 추적하고, 피드백을 수집합니다.
- 비용은 얼마나 차징이 되고 있는지, 응답 시간은 얼마나 걸렸는지 실시간으로 추적합니다.
- 데이터셋을 구성하여 LLM 어플리케이션을 자동 평가하고, 개발하는 일들을 도와줍니다.
이러한 핵심 기능들을 토대로 LLMOps라고 분류할 수 있으나, 개발사인 랭체인에서는 "Developer Platform" 이라고 칭하고 LLMOps라는 용어를 사용하지는 않습니다.
제 개인적인 의견을 덧붙이자면, LangSmith는 기본적으로 LLM 을 넘어 멀티모달리티를 지원하고, LLM 자체를 잘 만드는 것 보다 LLM 을 잘 사용하는 방법에 더 중점을 두고 있어서 LLMOps 라는 용어가 좋은 용어라고 보기는 어렵다고 생각합니다. 굳이 이름을 붙이자면, GenAIOps 라고 부르는게 더 맞겠네요.
사용 후기
간단한 RAG 시스템을 만들면서 만났던 어려움, 이를 해결하는 과정에서 LangSmith가 유용했던 점을 공유합니다.
목표와 결과물은 다음과 같습니다.
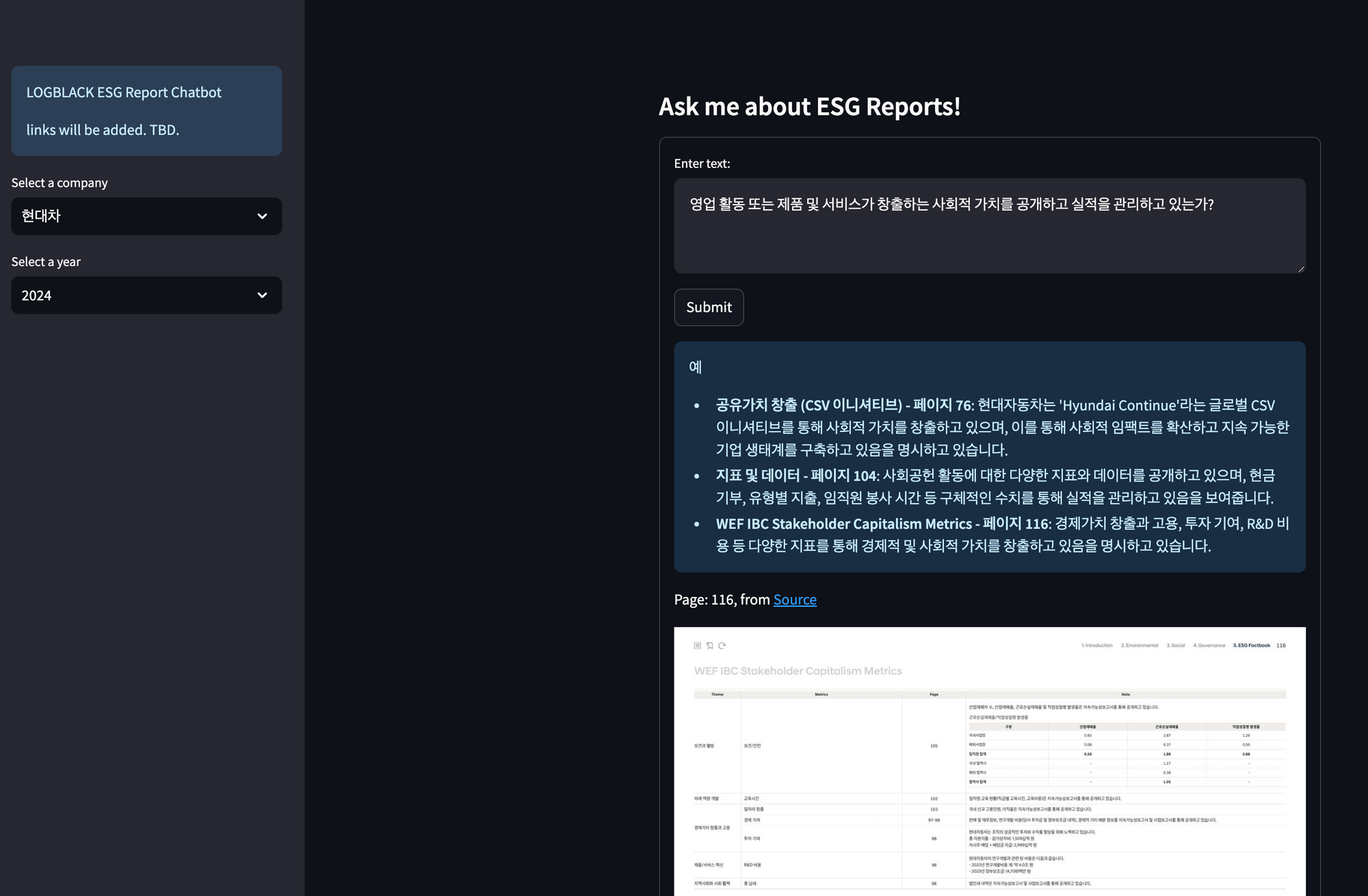
목표: 기업의 ESG 보고서를 분석하는 RAG 시스템
아래와 같이 회사와 년도를 지정하면, 당해 보고서를 분석하여 주어진 질문에 대해 분석 결과와 그 근거를 내놓는 RAG 시스템입니다. 이 시스템을 빌딩하며 겪었던 상황들을 설명합니다.
1. 추적과 디버깅
당연한 이야기이지만, 한번에 좋은 시스템을 만들기란 어렵습니다. 원하는 대로 결과를 나오게 만들려면, 프롬프팅도 수정하고, 데이터 전처리도 수정하고, 모델도 바꿔보고, 여러 과정을 거쳐야 합니다.
연구/개발자가 이 과정을 해나감에 있어서, 시작점은 직접 왜 대답이 만족스럽지 못한지 분석하고 해결해나가는 것이죠. 이 과정에 있어서 추적 (Tracing) 기능이 매우 유용했습니다.
저 같은 경우는 전문적인, 근거가 있는, 신뢰할 수 있는 답변을 원했습니다. 원문 보고서에서 적절한 페이지를 찾고, 이를 해석하고, 논리적으로 답변을 작성하는 것이 중요했죠. 당연히 첫 시도에서 이런 부분이 잘 안됐습니다.
왜 답변의 퀄리티가 만족스럽지 못할까?
이를 분석해야합니다.
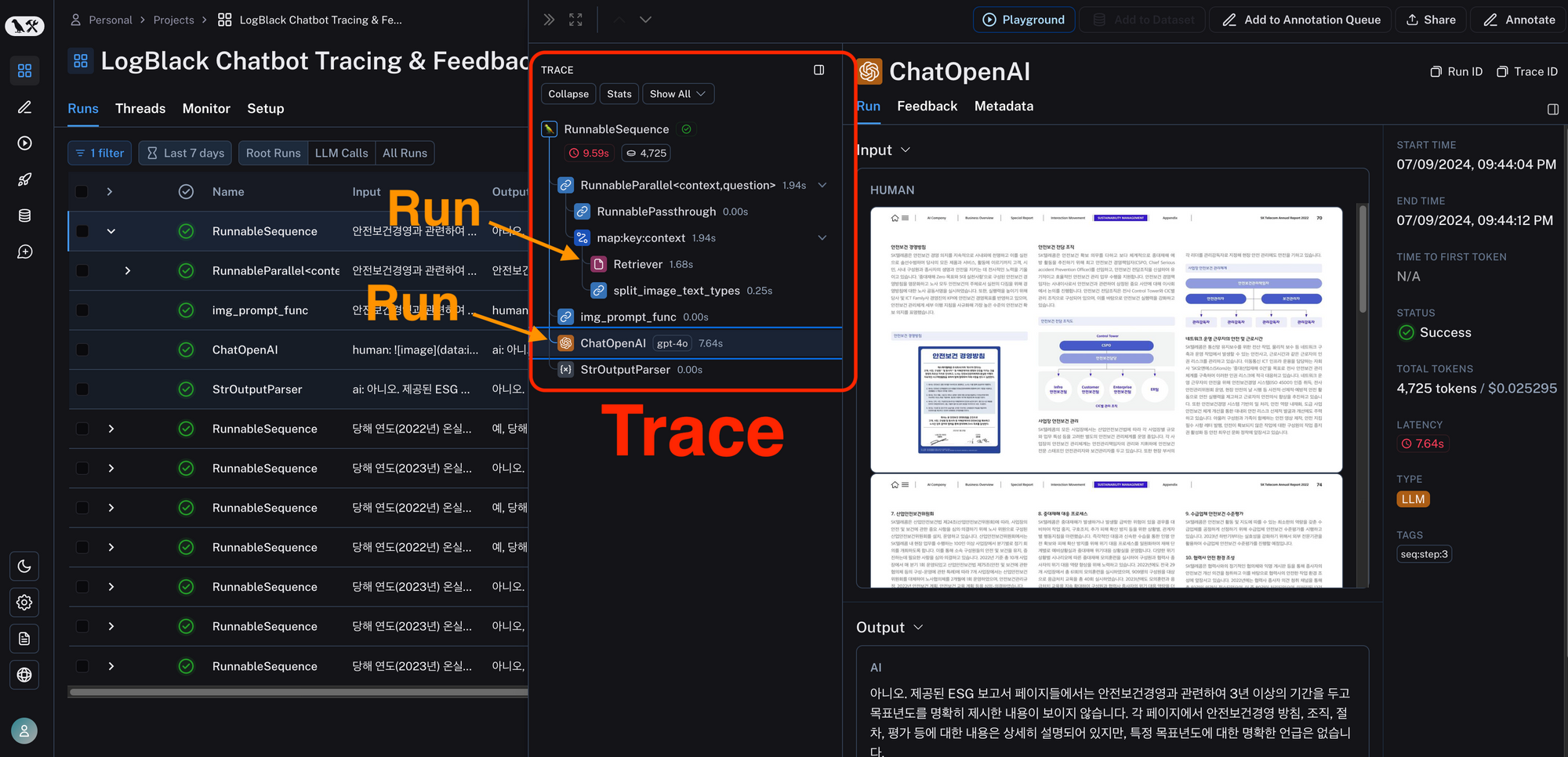
랭스미스에서는 위와 같이 각 중간 과정의 in/out 결과를 보여줍니다. Retrieve 가 잘 안되었는지, 올바른 근거 자료를 찾아 줬음에도 LLM이 대답을 못하고 있는지, 추론이 가능하죠.
LLM 모델을 바꾸거나, Prompt를 바꾸거나, 다양하게 모두 돌린후 간단히 비교하기도 좋습니다. 비용도 나오고, 수행시간도 나와서 어디서 비용이 많이 드는지, 너무 느리지는 않는지 모두 확인이 가능하죠.
제 경우에는 아래와 같이 개선을 했습니다.
- Retrieve가 문제임을 알았습니다, 원하는 근거가 잘 안 잡히더군요.
- 원본 보고서에서 표, 이미지, 글 들을 추출해서 요약하거나, 아니면 그대로 embedding을 시켰는데, 각 데이터들이 생김새도, 정보 밀도도 달라서 그런지 원하는 근거들 검색이 잘 안됐습니다.
- 원본 보고서를 하나의 의미, 같은 모양으로 나누기 위해 페이지 별로 요약을 돌리고 임베딩을 시켰는데, 이 때 요약 프롬프트가 정형화되도록 few-shot을 지정해 주는 것이 성능에 매우 큰 영향을 끼쳤습니다.
이 과정에서 이런 추적 도구가 없었다면, 디버깅? 연구? 하는 시간이 3배는 걸렸을 것 같네요. 왜냐하면
개선을 진행할 수록 소수의 질문에서만 문제가 생깁니다, 이를 체계화해서 로깅을 남기는 것은 구현하기가 귀찮아요.
직접 구현 다 하면 되지만, 그 시간을 단축시켜주는 도구로서 유용했습니다.
1.1 멀티모달리티 지원
추가로 저는 멀티모달리티 RAG 시스템을 구현했는데, 이미지의 피규어, 표 같은 시각 정보를 잘 추출하는 것이 필요했습니다.
다행히 랭스미스는 웹 인터페이스로 이런 in/out 이미지들을 모두 잘 보여줍니다. 수 많은 run 들에 대해 이미지 상태의 대화가 열람이 가능한 것이 매우. 편했습니다.
랭스미스의 대체제들 중, 랭퓨즈 (LangFuse) 도 무료 셀프호스팅 &. 오픈소스라는 장점이 있는데, 제가 사용하던 시점 기준으로는 멀티모달리티 지원을 아직 안 하는 것이 아쉬웠습니다.
2. 데이터 수집과 평가
LLM 어플리케이션의 알파이자 오메가는 사실 데이터셋이죠. 데이터셋을 구성하고 사용하기 좋게 잘 구성이 되어있습니다.
- 연구/개발자가 직접 데이터셋을 올릴 수 있고요, 허깅페이스처럼.
- 연동된 서비스의 유저 로그를 데이터셋으로 자동 수집이 가능하고요,
- 연동된 서비스의 유저 피드백도 같이 수집이 가능하고요,
- 자동으로 데이터를 가공해서 추가 수집이 가능합니다.
챗 서비스를 서빙한다고 하면, 유저의 질문, 시스템의 답변, 유저의 만족도 조사결과 까지 맞물려 데이터 수집이 되니 매우 유용합니다. 모아다가 강화학습을 할 수도 있고, A/B 테스트를 할 수도 있고, 불만족스러웠던 데이터만 따로 백테스팅을 할 수도 있고 사용하기 나름이죠.
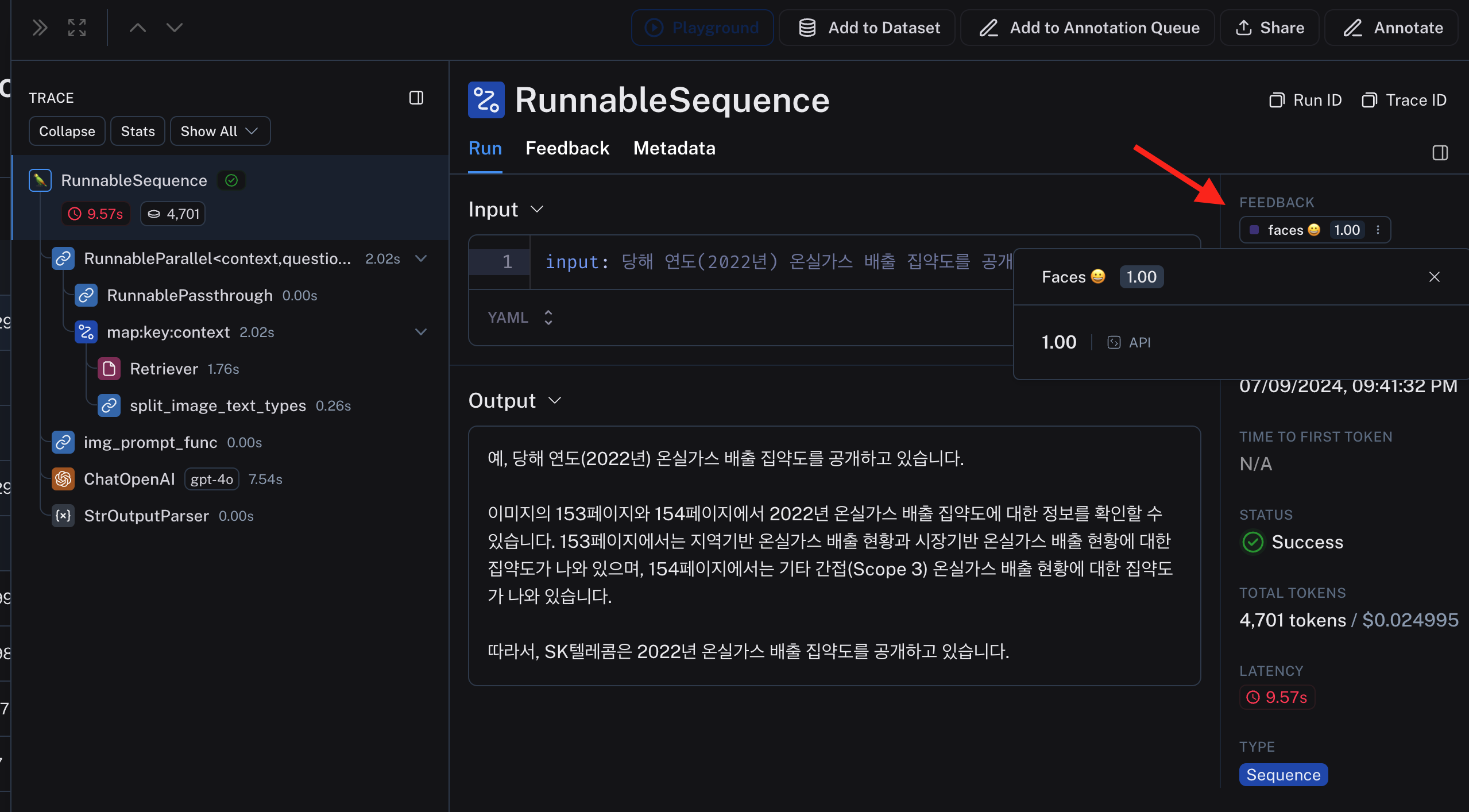
어떤 방식으로든 모아진 데이터는 평가에 활용을 하기 좋게 구성되어 있습니다.
자동/수동 평가가 모두 가능한데, 자동 평가가 매우 좋아요. 여기서는 Online Evaluation 이라고 부릅니다.
아래와 같이 평가 로직을 등록을 할 수 가 있는데, API key 와 함께 프롬프트를 써주면, LLM 이 또 알아서 평가를 해줍니다. 아래 그림은 답변이 도움이 되었는지를 수치화 하는 평가 로직인데, 프롬프트를 템플릿화 해서 다 만들어놔서 편합니다. 제가 안만들어도 그냥 가져다가 쓸 것이 많이 있습니다.
평가 로직을 등록만 해두면, 서비스에서 발생하는 내 답변들을 자동으로 평가해 데이터화 해줍니다.
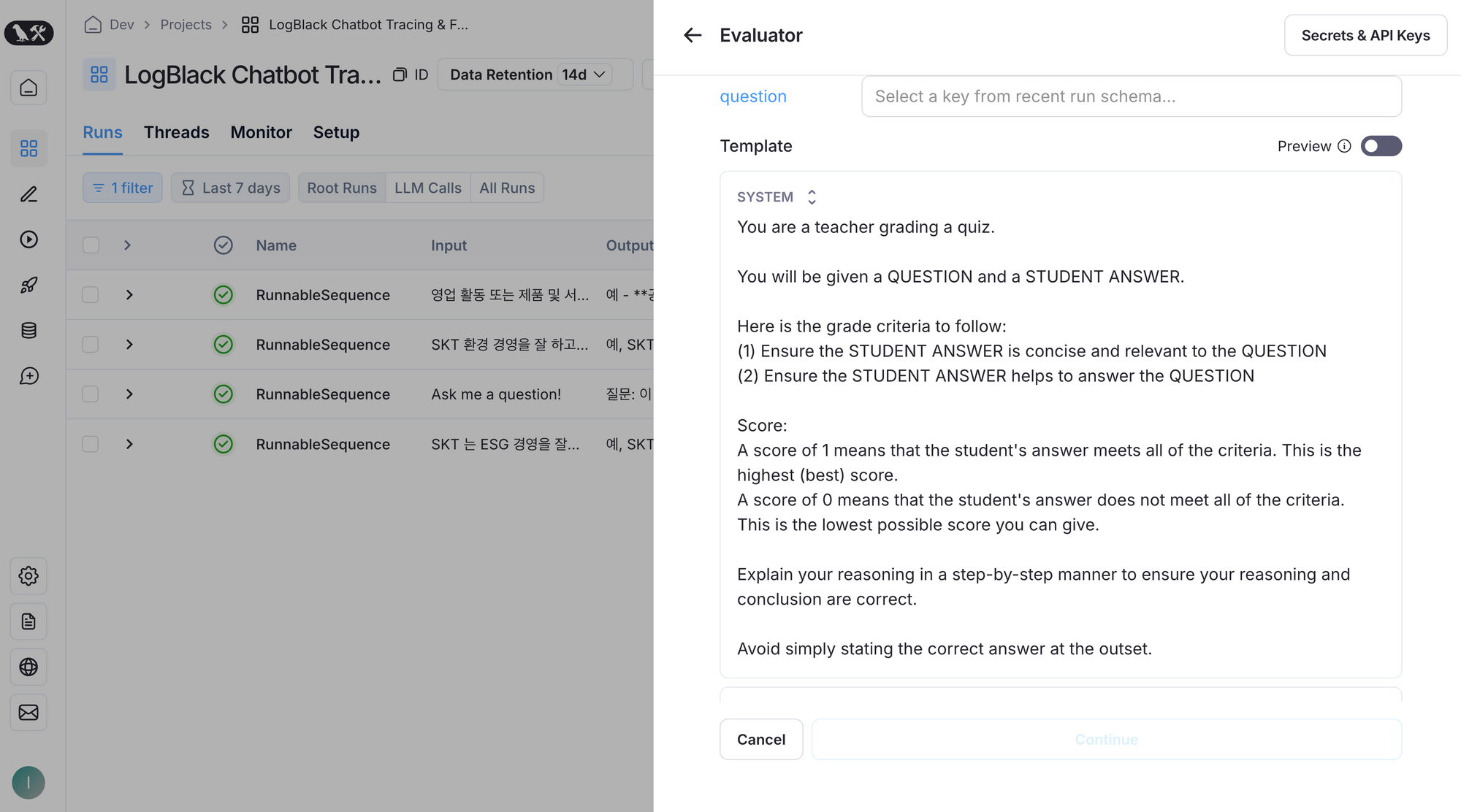
LLM 어플리케이션은 "평가" 가 매우 어려운 경우가 많습니다. 정성적이라서요. 이 부분을 해결하기 위해 양질의 데이터, 수많은 양의 데이터, LLM 을 다시 평가 판사 (LLM as judge) 로 사용하기, 외 기타 여러가지 방법이 있습니다. 이를 잘 지원하는 도구로서 유용합니다.
그래도 완벽한 평가는 아직 많이 어렵네요.
여기서 설명한 데이터 수집/ 평가 외 다양한 기능들이 아주아주아주 많이 있습니다. 필요에 맞게 사용할 것들이 있어서 참 좋습니다.
3. 협업
위 평가와 맞물리는 내용인데, 많은 경우에 이런 시스템은 혼자 만들기가 어렵죠. 저 같은 경우도, ESG 잘 모릅니다. ESG 전문가 분들은 따로 있습니다. 이 분들이 데이터를 분석하고, 평가해서 데이터 라벨링을 해주고, 의견을 주고 해야하는데, 협업하기가 쉽지 않습니다.
데이터를 어떤 형태로 뽑아 드려야 할지, 그 분들은 어떻게 라벨링을 달아서 시스템에 다시 올려야할지 막막한데요, 이 부분을 잘 도와줍니다.
데이터들을 Annotation queue 에 넣어서 사람을 지정해 줄 수 가 있습니다. 그럼, 전문가 분들이 데이터를 보고 정성평가를 달아주고, 데이터셋에 연동이 됩니다. 모두 웹인터페이스로 사용이 가능해서, 개발이 익숙하지 않으신 분들과의 협업이 매우 편합니다.
협업 기능을 잘 쓰려면 비용을 내야 하는 데, 충분히 낼 만한 가치가 있다고 생각이 됩니다.
총평
거의 광고 수준으로 칭찬을 했는데, 제 경험이 매우 좋아서 그렇습니다. 다른 대체제들도 있지만 사용해 보지는 않아서 비교는 못해 아쉽네요. 어쨌든 LLM 시스템 개발에 유용한건 사용해보신 분들이라면 누구나 동의할 수준이라고 보입니다.
위에서 말한 내용 말고도 장단점을 꼽자면, 이정도로 요약이 가능합니다.
- 사용하기가 매우 쉽습니다, 문서도 잘 되어있고 코드 구현도 쉬워요.
- LangChain 이랑 같이 사용하면 더 쉽고, 잘 연동 됩니다.
- 오픈소스가 아니라서 상업 수준으로 사용하려면, 비용을 내야합니다.
제가 마침 이 내용을 SKT 에서 개발자 분들을 대상으로 강의하게 됐습니다. 현업분들하고도 이야기를 나눠보니, 이미 비슷한 플랫폼을 사용하고 계시기도 하더군요.
공통적으로 느낀점은 "평가"를 어떻게 잘 할 것인가에 대한 고민이 많습니다. 저도 고민이 많은 부분입니다.
LangSmith를 비롯한 LLMOps라고 불리는 도구들은 이를 도와줄 뿐, 직접 해결해 주지는 않습니다. 정답이 없는 문제거든요. 어려운 만큼 좋은 도구가 더욱 필요하다고 생각이 드네요.
모두들 꼭 한번 써보시길 추천드립니다. 진짜 좋아요. 그래서 이 포스트도 작성하게 되었습니다.