CycleGAN : Image Translation with GAN (4)


Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks (CycleGAN) from UC Berkeley (pix2pix upgrade)
&
Learning to Discover Cross-Domain Relations with Generative Adversarial Networks (DiscoGAN) from SK T-Brain
DiscoGAN & CycleGAN
- Almost Identical concept.
- DiscoGAN came 15 days earlier. Low resolution ($64 \times 64$)
- CycleGAN has better qualitative results ($256 \times 256$) and quantative experiments.
Difference from DTN
- No $f$-constancy. Do not need pre-trained context encoder
- Only need dataset $S$ and $T$ by proposing cycle-consistency
DiscoGAN
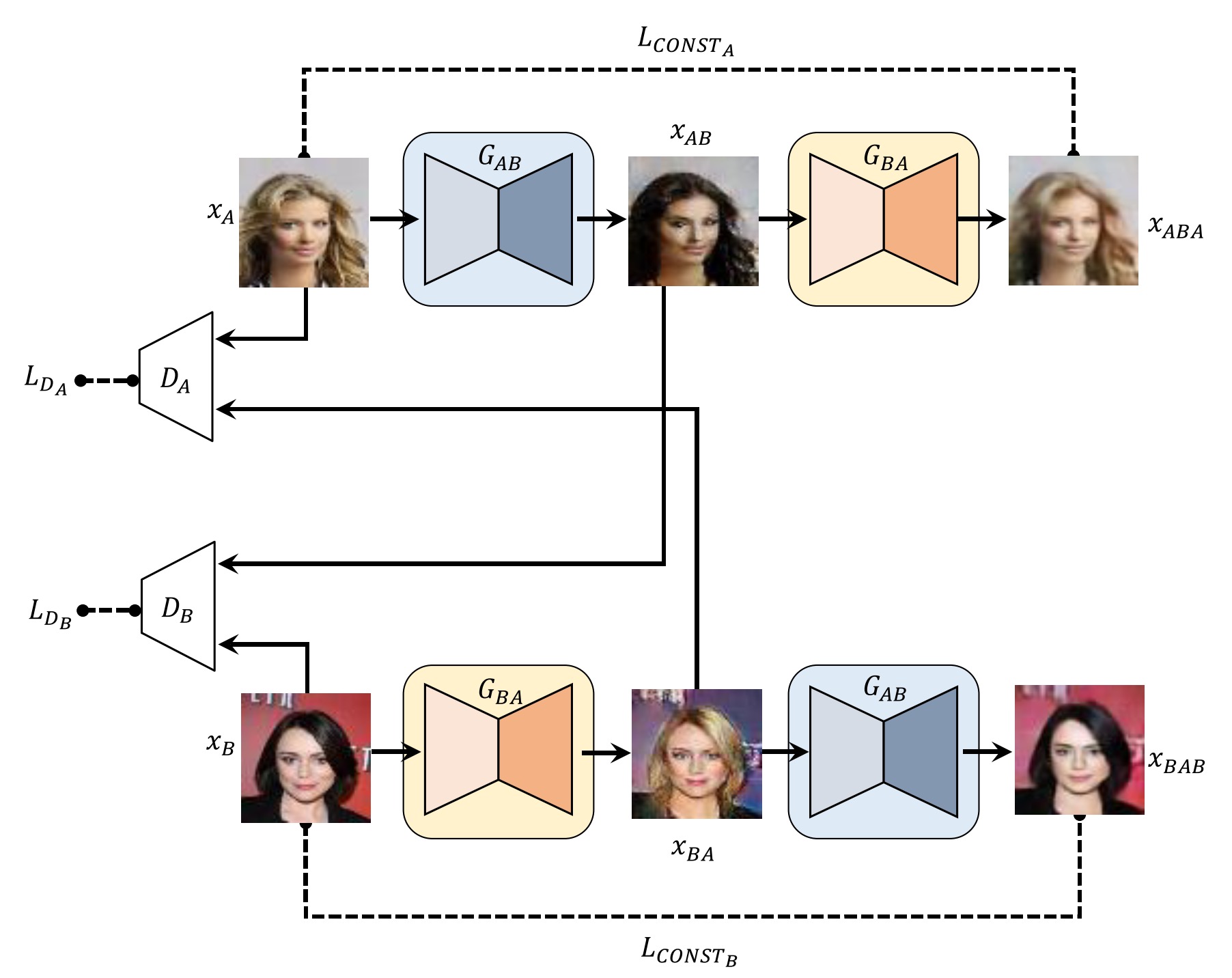

without cross domain matching, GAN has mode collapse

learn projection to mode in domain $B$, while two domains have one-to-one relation
Typical GAN issue: Mode collapse


- top is ideal case, bottom is mode collapse failure case
- Toy problem of 2-dim Gaussian mixture model
- 5 modes of domain A to 10 modes of domain B

- GAN, GAN + const show injective mapping & mode collapse
- DiscoGAN shows bijective mapping & generate all 10 modes of B.
proposed DiscoGAN
CycleGAN has similar contribution on this point


Results


codes and more results in
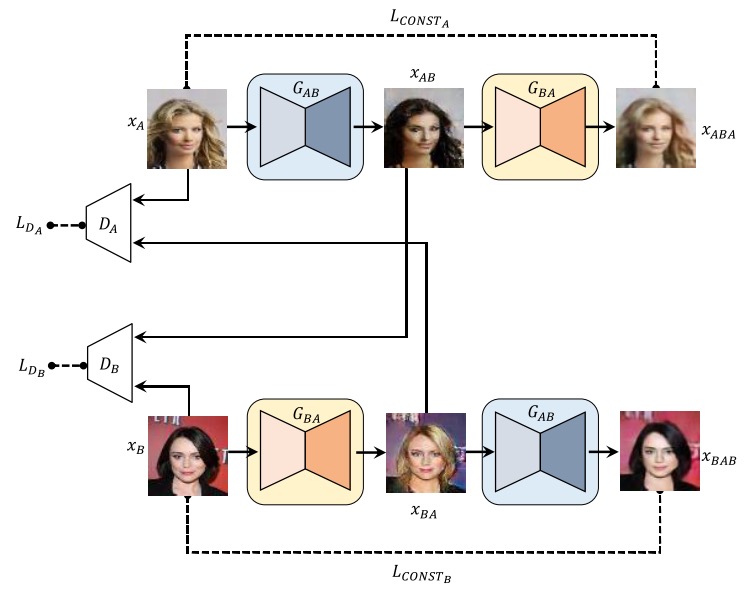
CycleGAN

Use more GAN techniques: LSGAN, use image buffer of previous generated samples





failure case

CycleGAN demonstrates more experiments!
project page : https://junyanz.github.io/CycleGAN/
code available with Torch and PyTorch