Pascal - NVIDIA의 새로운 GPU architecture 발표


드디어 NVIDIA 에서 새로운 Pascal GPU를 발표했다.
이미 몇 달전에 일부(?) 공개가 되었고, 루머들도 많아서 관심있는 사람들은 미리 좀 알았겠지만 까보니 흥미로운 것들이 좀 있다.
개인적으로 가장 놀라운 것은 half-precision! (Deep learning 시장을 어지간히도 먹고 싶긴 하나보다.)
자 그럼, 주목할만한 것들을 살펴보자.
Pascal 이 뭔가요?
NVIDIA는 2000년대 중반부터 자사의 GPU architecture에 이름을 과학자 이름들을 붙이기 시작했다.(Tesla --> Fermi --> Kepler --> Maxwell --> Pascal)
변천사는 아래 그림과 같고 이번이 Pascal, 다음이 Volta라고 예정되어있다.
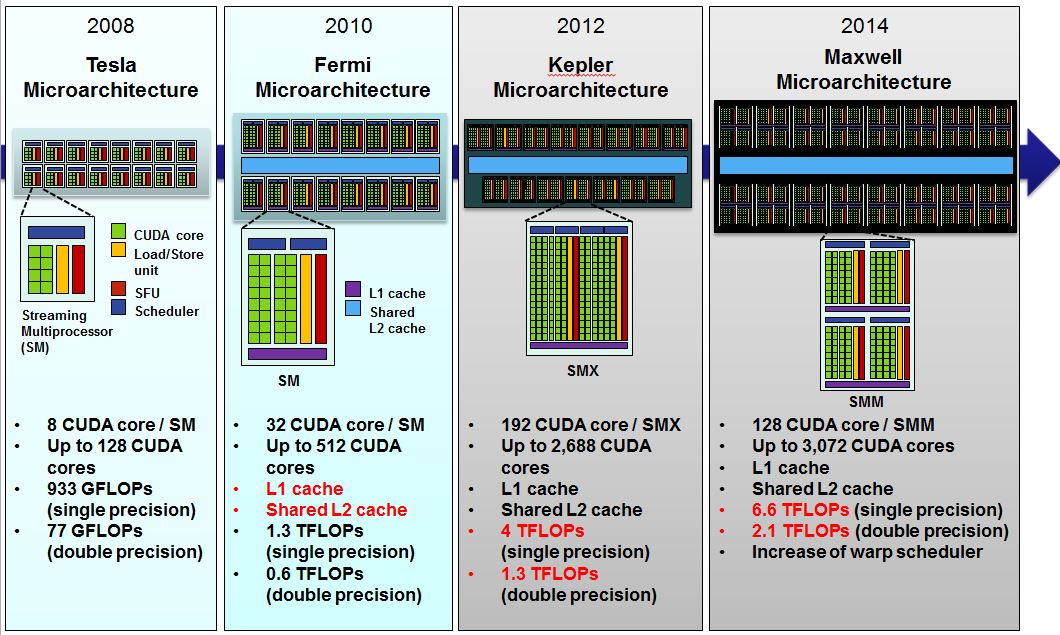
NVIDIA GPU의 브랜드인 Geforce (게임용), Quadro (전문가용), Tesla (슈퍼컴퓨팅용, 저 위에 있는 Tesla architecture 랑 이름만 같고 다른거다.)에 시간순으로 GPU architecture 가 적용되어 있다.
예를 들면, Geforce GTX 480,580은 Fermi architecture이고, GTX 680은 Kepler, GTX 980은 Maxwell 이다.
앞으로 나올 GTX 1080은 Pascal 일 것이고, 이번에 발표한 것은 Tesla p100 GPU 이다.
보면 알겠지만 당연히 시간이 갈수록 CUDA core 는 많아 지고, TFLOPS는 들어난다.
그래서 달라진 점?
한 페이지에 요약이 잘 되어있는 표를 anandtech에서 퍼왔다.
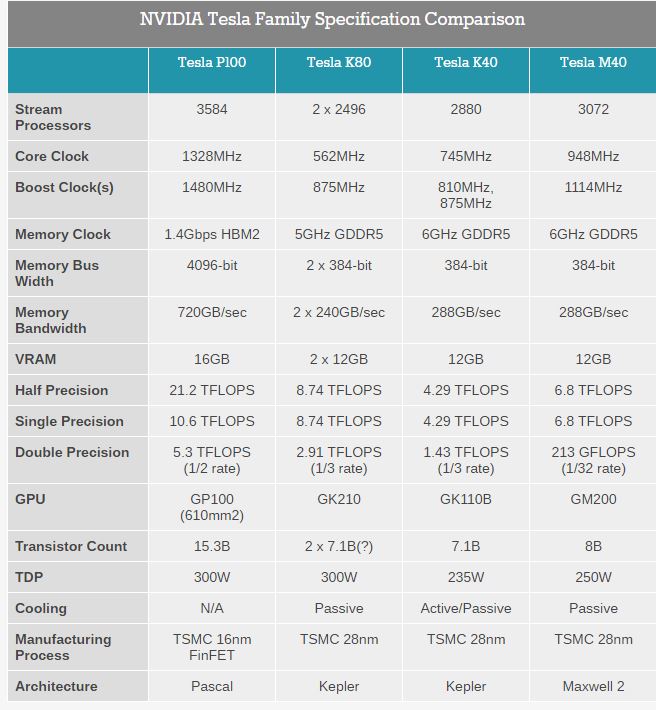
자주 보던 사람들이 아니면 보기 어려우니 내가 보기에 중요한 것들을 list up 해보겠다.
우선 루머 및 각종 정보들을 통해 알려진 것들 부터 보면.
-
공정이 28nm 에서 16nm FinFET으로. 이는 물리적으로 훨씬 많은 트랜지스터를 박아 넣을 수 있음을 의미하며 그래서 M40에 비해 약 2배가 늘었다. (8B --> 15.3B, B는 billion 이다.)
-
GDDR5 에서 HBM2으로. 잘 아는 사람 아니면 어려울 수 있는데, 대충 설명하자면 메모리의 세대(?)가 변했다. 그 결과로 Memory bandwidth가 288GB/sec 에서 720GB/sec로 늘어났다. Memory bandwidth는 GPU 에서 성능 향상의 발목을 잡는 주요 원인으로 꼽혀 있던 요인이다.
그리고, 다소 눈에 띄는 점을 찝어보면.
-
Stream Processors 가 고작 3072개에서 3584개로. 위에서 말했듯이 트랜지스터가 2배가 되었는데, Stream Processor (CUDA core 이자 ALU 라고 보면 된다.)가 조금밖에 안늘었다. 추가된 트랜지스터를 딴 곳에 투자했다는 이야기. 이제까지 변화했던 추세랑은 많이 다르다. 어떻게 해석해야할지 다음 섹션에서 조금 더 자세히 다루겠다.
-
Clock이 948MHz에서 1328MHz로. 공정이 내려갔으니 당연히 구동 power 가 줄어들었고, 이는 클럭의 상승으로 나타났다. 하지만 TDP는 300W....
불나겠다 이놈들아. -
Double Precision 연산이 213GFLOPS 에서 5.3TFLOPS로. 엄청 늘었다. 무려 25배?. 사실 Kepler때 double precision이 높았는데, Maxwell 에서 대폭 깎았었다. 이를 Kepler때보다도 더 올렸다. 이유가 궁금하다. 슈퍼컴퓨팅 시장에서 double precision 수요가 있다고 판단하는가 보다.
마지막으로 가장 눈에 띄는 점!
- Half precision 지원!! 내생각에는 이게 가장 신박한점이다. NVIDIA 에서 주장하는 Deep learning 성능이 눈에 띄게 증가했다는 점 중 하나가 이 것이다.
(컴퓨팅 관점에서는 반쯤 사기라고해도 무방한 것 같은데...)
이것 또한 다음섹션에서 자세히 설명하겠다.
논의 할 만한 점
위에서 설명한 점들 중 Stream Processor 갯수와 Half precision 에 대한 이야기를 좀 자세히 하고자 한다.
우선 Stream Processor 가 많이 증가하지 않은 이유.에 대해서 이야기 하고자 한다. 상식적(?)으로 가장 기본적인 연산자원이 많아 지면 성능이 증가할 것이라고 생각하는 것이 일반적인데, 왜 그렇게 stream processor를 늘리지 않았을까?
첫째 이유는 stream processor를 늘려봤자 성능이 다른 요소들 (대표적인 예가 memory bandwidth)에 의해 올라가지 못할 것이라는 것이다. 실제로 많은 연구들이 이런 문제를 지적했고, stream processor 가 상당시간 동안 놀고 있다는 것이 증명되었다. 특히, 슈퍼컴퓨팅 분야에서는 그런 상황이 많은 것으로 보고 되고 있다. 위에서는 언급하지는 않았지만, register file 사이즈도 더 커졌는데 (무려 14MB....) 같은 이유에서 일 것 이다.
두번째 이유는 아마도 dark silicon 문제가 아닐까 싶다. dark silicon 문제는 이 쪽 분야에서 심각(?)하게 받아들이고 있는 문제인데, 대충 말하자면 stream processor가 많아봤자 발열 때문에 다 돌릴수도 없고, 돌려봤자 이득도 없다는 것이다. 그래서 남는 트랜지스터를 double precision 유닛으로 돌린 것이 아닌가 싶다. 실제로 이러한 이유로 CPU에 내장 GPU가 끼어 들어간지 5년정도 되었다.
그리고, 가장 중요하다고 생각되는 half precision 이야기를 하고자 한다.
우선 half precision 이 무엇인지 부터 설명하자.
컴퓨터에서는 소수를 제한된 데이터로 나타내야하기 때문에 완벽히 정확할 수 없다.
그래서 32bit의 데이터로 소수를 나타낸 것이 single precision이다 (C언어에서 float). 64bit의 데이터를 써서 더 정확하게 표현하는 것이 double precision 이다 (c언어에서 double). 그렇다면 half precision은 16bit만을 이용하여 덜 정확하게 표현한 것이다.
Half precision이 어디에 쓰일 수 있길래 만들었을까? 당연히 deep learning 이 타겟인 것 같다. 실제로 NVIDIA 발표자료에서도 이렇게 이야기 하고 있다. deep learning 관련해서는 이 블로그에 글도 많으니 따로 설명은 안하겠다. 중요한 것은 deep learning의 연산이 half precision으로도 충분하다는 것이다. 애초에 정확한 연산이 필요없는 것이니 말이다.
하드웨어적으로 어떻게 한 것이냐? Stream processor는 기본적으로 ALU랑 비슷하다고 볼 수 있다. 따라서 각 precision 마다 연산기 회로가 필요한데, 여기에 half-precision path를 추가한 것 일테다. 이 때까지는 half precision 연산을 쓰는 일이 거의 없었기 때문에 하드웨어적인 지원이 없었고, 위의 표에서 알 수 있듯이 single precision의 성능과 같다 (이는 32bit 연산을 다하고 16bit를 버린다는 것).
첨언을 좀 하자면, 연산 결과의 정확성을 조금 버리더라도 더 좋은 성능을 내는 기법 (Approximate computing, 근사 컴퓨팅)이 최근 몇년간 연구가 활발히 진행되어왔다. 그래서 기술적으로 아주 특별한 것은 아니다.
추가로, NVIDIA에서 배포하는 deep learning 라이브러리인 cuDNN 도 새로 발표했다. 당연히 이 half precision을 열심히 써서 엄청 빨라졌겠지. deep learning 하시는 분들 신나겠네..
Deep learning을 위해 이렇게 까지? NVIDIA 입장에서는 이제 graphics 시장외의 다른 시장을 더 찾고 있는 상황이다. 그 첫번째 노력이 GPGPU이다. CUDA를 만들고 그래픽스 이외의 컴퓨팅시장에 뛰어 든 것. 매우 성공적으로 잘 나가고 있다. 이런 상황에서 deep learning은 GPGPU에 힘입어, 아주 가파르게 분야가 발달하고 있다. 여러 정황상 VR, 자율주행자동차 등을 주요 타겟으로 하고 있는 것으로 보이는데, 앞으로 자동차에 GPU를 한대씩 팔아먹는다고 생각해보자. NVIDIA 는 더 부자가 되겠지... 실제로 몇년 전부터 NVIDIA는 deep learning 관련 연구진에 후원을 아주 적극적으로 진행해 왔다.
결론 및 요약
어머! 이건 사야해!
처음 발표한 것이 슈퍼컴퓨팅용 GPU이지만 Geforce 계열도 별반 차이는 없을 것이다.
예고된 대로, 이제까지의 변화들보다 훨씬 큰 변화가 많았다. 대표적인 것이 공정과 메모리. 거기에 deep learning을 위한 half precision 까지.
(하.. AMD야 일 좀해라...)
점점 더 게임보다는 컴퓨팅에 초점을 맞춰 나가는 것 같다. 앞으로도 이렇게 계속 발전 할 것으로 보인다. 조만간 컴퓨터, 핸드폰 이외의 기계 (아마도 자동차)들에 GPU가 들어갈 것으로 예상된다.